
Research
- Hardware
Support for
Software
Integrity (Secure Processors)
- Trace Compression
- TinyHMS (Tiny Wireless Sensor Networks for Health Monitoring)
- Performance Evaluation
- Workload
Characterization
- Bridging the CPU-Memory Speed Gap




Secure Processors
"The art of war teaches us to rely not on the likelihood of the enemy’s not coming, but on our own readiness to receive him; not on the chance of his not attacking, but rather on the fact that we have made our position unassailable.”The Art of War by Sun Tzu
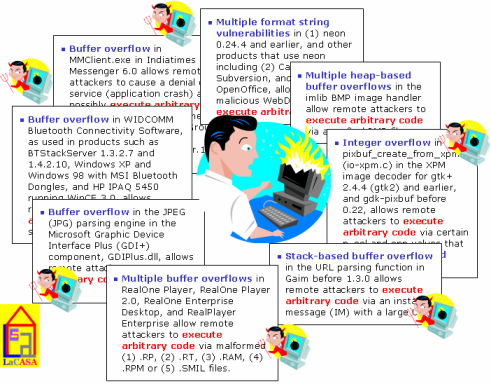  |
Current economic and technology trends will further
increase our
reliance on highly interconnected and deeply embedded computing
systems. These trends underscore the utmost importance of computer
system security. Failing to resist system faults and malicious attacks
can incur significant direct costs, as well as costs in lost revenue
opportunities. This problem can be addressed at different levels, from
more secure software and operating systems, down to solutions based on
hardware support. The majority of the existing techniques tackle the
problem of security flaws at the software level, lacking generality,
often inducing prohibitive overhead in performance and cost, and
generating a significant number of false alarms. On the other hand, the
ever-increasing number of transistors on a chip allows us to look
beyond performance improvements to increased system resilience to
attacks. With more complex software having potentially a
larger number of defects, increased number of attacks, and
proliferation of networked computing platforms, we believe that
dedicated processor resources should be used to provide more secure
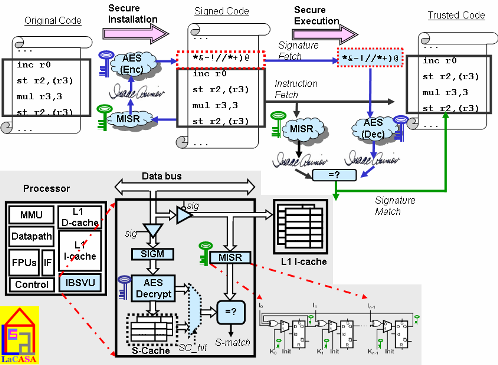
execution. Our research focuses at new computer architectures that will ensure software integrity through hardware extensions. As a result of this effort, we have proposed a novel hardware mechanism for runtime verification of software integrity using encrypted instruction block signatures. We are currently working on several implementations suitable for various computing platforms (server, desktop, and embedded); these implementations promise to counter malicious attacks at minimal performance and power overhead with minimal additional on-chip area. The proposed implementations differ in the type of protected instruction blocks, placement of instruction block signatures in address space and physical memory, and signature handling after verification. Several of these implementations have proved to have very low performance overhead and are applicable to both embedded and high-end processors. [CASES05] [WASSA04] [ACMSE04] |
Back to Top
Trace Compression
 |
Novel research
ideas in computer
architecture are frequently
evaluated
using trace-driven simulation. Traces can accurately represent a system
workload,
and in the last decade there has been a lot of research effort
dedicated
to trace issues, such as trace collection, reduction and processing. To
offer
a faithful representation of a specific workload, traces must be very
large,
encompassing billions of memory references and/or instructions. For
example,
an instruction trace with 1 billion instructions, where each trace
record
takes 10 bytes requires almost 10GB of storage space. Yet, with a
modern
superscalar processor executing 1.5 instructions each clock cycle on
average
and running at 3 GHz, it will represent only 0.2 seconds of the CPU
execution
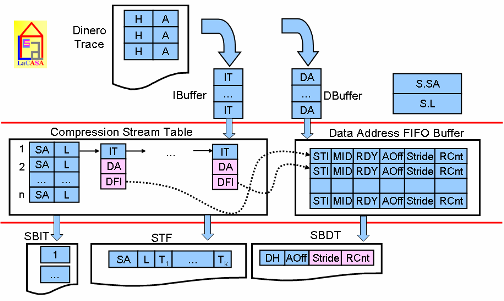
time. Although traditional compression techniques based on Ziv-Lempel algorithm offer good compression ratio even further reduction of traces is needed. We investigate new methods for trace compression that exploit inherent characteristics of instruction and data traces such as basic blocks, streams, and spatial and temporal locality. We have developed SBC (Stream-Based Compression), a new technique for compression of instruction and data address traces. Utility programs and actual traces for SPEC CPU2000 benchmarks can be found here. [CA03][WWC03] |
Back to Top
TinyHMS (Tiny
Wireless Sensors for Health
Monitoring)
  |
Recent
technological advances in
sensors, low-power microelectronics and miniaturization, and wireless
networking enabled the design and proliferation of wireless sensor
networks capable of autonomously monitoring and controlling
environments. One of the most promising applications of sensor networks
is for human health monitoring. A number of tiny wireless
sensors, strategically placed on the human body, create a wireless body
area network that can monitor various vital signs, providing real-time
feedback to the user and medical personnel. The wireless body
area networks promise to revolutionize healthcare services and address
the imminent crisis in healthcare systems due to current demographic
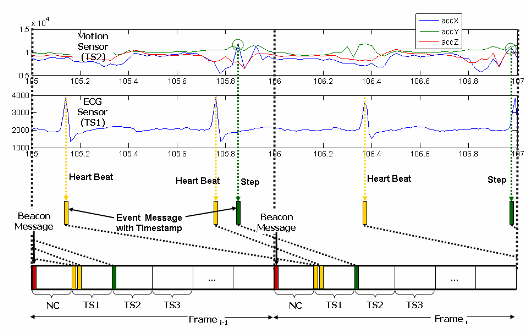
and economic trends. In collaboration with Dr. Emil Jovanov, we have been working on a number of projects related to wireless body area networks (WBANs). These projects span accross multiple system layers, including hardware development of wireless sensors, software development for sensor nodes (sampling, processing, communication); network protocols and optimization; software development for PDAs and personal computers; higher-level data integration and representation; and system support for healthcare services. We have developed several research prototypes and continue to seek for new techniques that will further improve reliability, functionallity, and cost-effectiveness of these systems, as well as user compliance. Example projects are development of algorithms for step detection on accelerometer-based motion sensors (extremly resource-constrained systems) and development of algorithms for on-sensor real-time detection of arrythmias. We are always looking for smart individuals that are ready to give their best ideas and skills in shaping this emerging field. On the right is a photo of our recent prototype (top) and real ECG and accelerometer signals augmented with events (detected on sensors) and corresponding TinyOS messages (it was me walking with the ECG sensor and a motion sensor on my knee). [COMPCOMM06] [JNER05] |
Back to Top
Performance
Evaluation & Workload
Characterization
  |
In order to achieve
optimum
performance of a given application on a
given
computer platform, compilers must keep up with new processor features,
such
as extended instruction set, pipelining, multiple-level cache
hierarchy,
instruction level parallelism, and branch prediction, exploiting new
optimization
possibilities. Although compilers for new processors do include some
advanced
optimization features they are specifically told by program developers
for
which architecture to optimize, by using different compiler switches or
using
CPUID. We believe that future compilers must be even more aware of the
underlying
architecture. However, internal architectural details are seldom made
public.
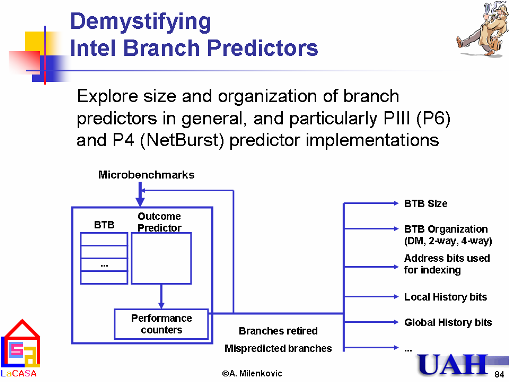
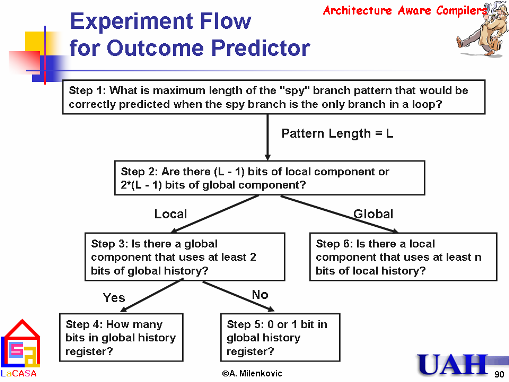
We have recently proposed an experiment flow with a series of
microbenchmarks
that determine the organization and size of a branch predictor using
on-chip performance monitoring registers. Such knowledge can be used
either for manual code optimization, or for design of new, more
architecture-aware compilers.
It could also be used for verification of architectural simulators.
Microbenchmarks
for determining branch predictor organization are originally presented
in
our WDDD'02
paper. The proposed experiment flow is illustrated with microbenchmarks
tuned for Intel Pentium III and Pentium 4 processors. Our group is interested in workload characterization of current and future applications for various computing platforms. Starting from relatively small applications running on low-cost, low-power embedded systems, to multimedia applications (video encode/decode, speech recognition/synthesis, compression) running on mobile handheld platforms, to scientific applications, large-scale databases, e-commerce and decision-support applications running on high-performance servers. The LaCASA Laboratory uses SPECcpu, MiBench, and SPLASH-2 benchmark suites we are looking for new real-world applications. [SPE04] |
Back to Top
Bridging the
CPU-Memory Speed Gap
| The underlying
semiconductor
technology continues to improve
significantly
doubling the number of transistors per processor chip every 18 months
and
increasing the operating frequency. This opens a way for a
billion-transistor
processor chip running at 20 GHz by the end of this decade. While
memory
capacity improves significantly, quadrupling in 3-4 years, the memory
latency
improves slowly since the requirements for high capacity, high speed
and
low cost are in direct opposition. We investigate both hardware and software techniques aimed to overcome this increasing speed gap between processor and memory subsystems in a wide range of computing systems, starting from low-cost embedded systems, to high-performance processors and multiprocessor systems. Our prior work has explored cache coherence protocols and techniques for tolerating memory latency in shared memory multiprocessors. Specifically we investigated the performance and implementation issues of hardware and software-controlled cache prefetching and data forwarding. We also proposed a novel technique cache injection and showed that cache injection can achieve significant performance improvement in bus-based shared memory multiprocessors. Our recent work concentrates on cache efficiency and dynamic behavior in embedded systems. We are also interested in cache replacement policies in both high-performance and embedded systems. Replacement policy is one of the key factors that determine the effectiveness of caches and specifies which cache block should be replaced on a cache miss. Its importance is expected to grow further in the future as capacity and associativity of caches increase. An optimal replacement algorithm would replace a block whose next reference is farthest away in the future; this requires the perfect knowledge of future block references, and hence is infeasible. Instead, we have to use heuristics to determine which block is the most suitable to be replaced. We have done an extensive performance analysis of the existing replacement policies. |
Back to Top